research
“The thing about speech is, it varies.” (Remirez, in press). But for a number of historical and disciplinary reasons (see McGowan, in press), it feels normal for people in my field to talk about how listeners are “confronted with” tremendous variation in speech or to think about and write about variation as a big problem that listeners have to solve. I think this is a real shame.
Hi! My research takes the position that listeners are sensitive to patterns of covariation in speech and that knowing (more on ‘knowing’ later) these subtle patterns is part of what it means to truly know a language.

Why? Because speech is social. When we speak, we communicate not only our ideas, but also numerous social cues about who we are, where we come from, what we think you already know, who we think is listening, and many other details…
Which is great because if people sound the way we expect them to, we’re able to understand them better (McGowan, 2015; 2012 LSA presentation)
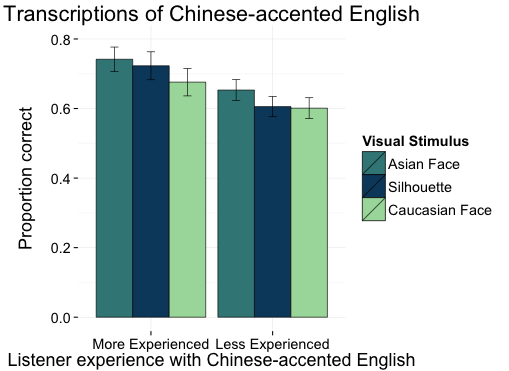



This is true even when our expectations are based on stereotypes rather than authentic experience (McGowan, 2016)!
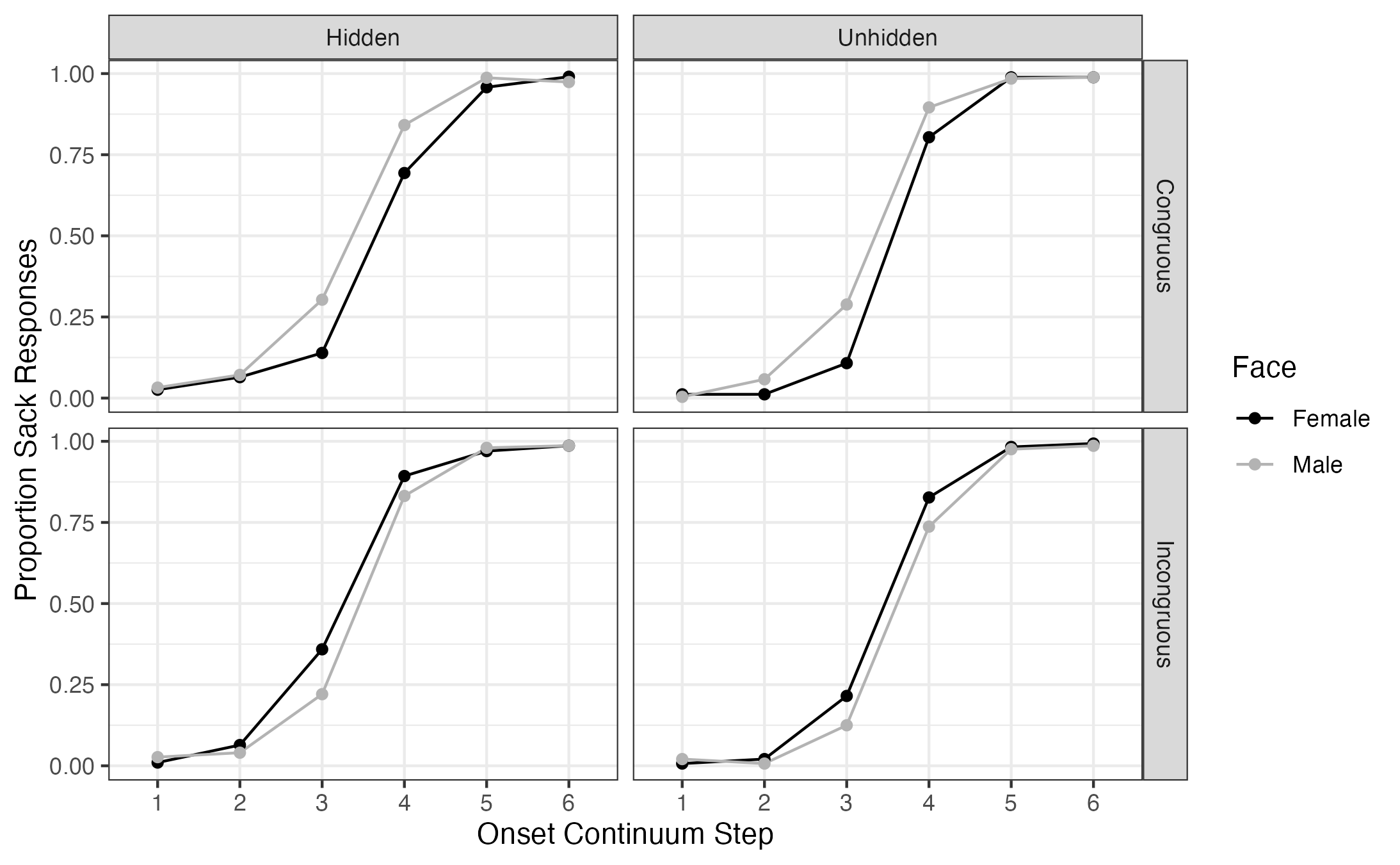
In Sumner, Kim, King, and McGowan (2014) we propose a model (below) of how the linguistic and the social aspects of speech interact to support perception.
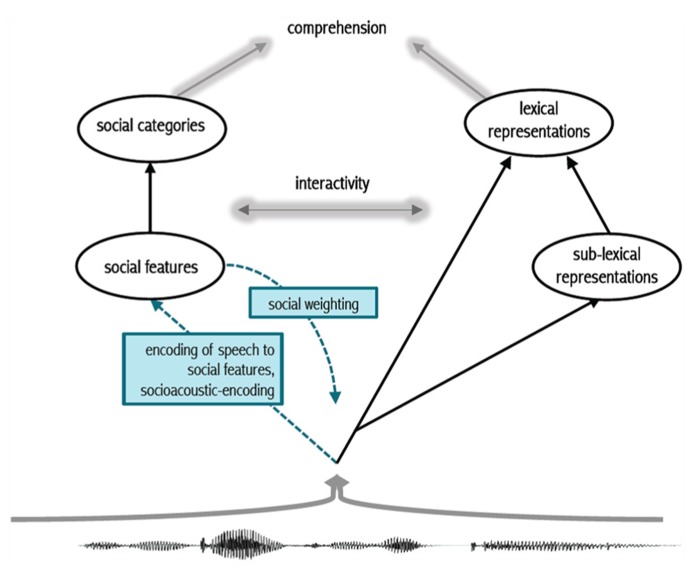
In this model, we propose that listeners process both phonetically cued social information and phonetically cued linguistic information (this is Meghan Sumner’s excellent terminology) prior to word recognition and that these dual routes can interact to guide and facilitate perception.
For example, when Anna Babel and I told Bolivian listeners to expect Quechua-accented Spanish, they perceived vowels completely differently than if they were told to anticipate a Spanish accent (McGowan and Babel, 2020)
This suggests that experienced listeners have detailed knowledge of phonetically-cued social information —so expecting the variation consistent with a particular social category can change the way we perceive vowels. Social information isn’t noise to be thrown away, it is an essential part of the signal.

nbsp;
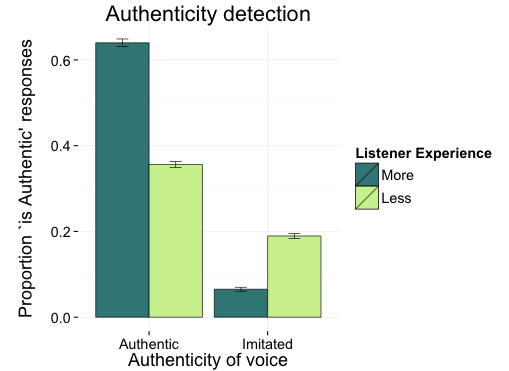
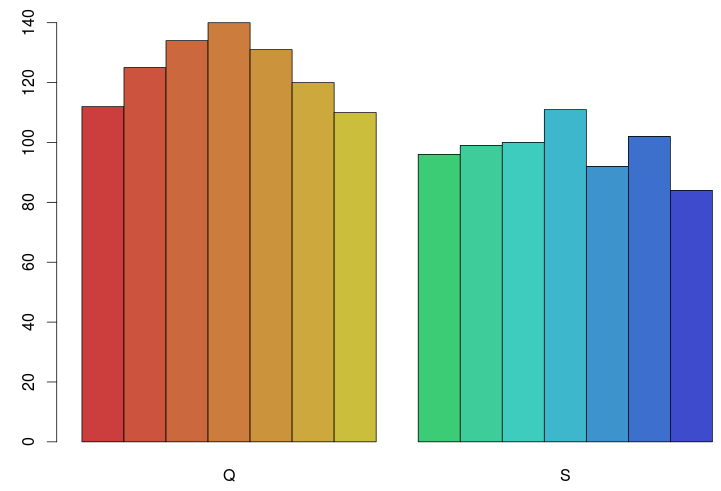
But what would happen if, instead of misleading listeners about the identity of the talker, we explicitly told them to ignore the guise information?
The answer is nothing! There is no difference in listeners’ use of the visual guise when told to ignore it/that it is meaningless (see figure, left). But, when Kyler Laycock and I conducted a Matched-Guise Experiment in which visual information about the gender of the talker was sometimes congruent with the voice and sometimes incongruent with the voice, we replicated the Strand Effect, the second experiment of Strand & Johnson (1996) in which visual information influences listeners’ perception of fricative consonants (top row of figure).
But, similar to the results of the 2nd guise presentation in Bolivia and with Chinese-accented English among experienced listeners, when the gender information in the voice and the visual presentation were incongruous, it once again appears that listeners attend more strongly to the acoustic signal than to the visual signal (bottom row of figure). It is unclear if this would happen with a more convincing/informative visual signal (e.g. video); so we’re testing this now.
So does all this knowledge and sensitivity only apply to social variation?
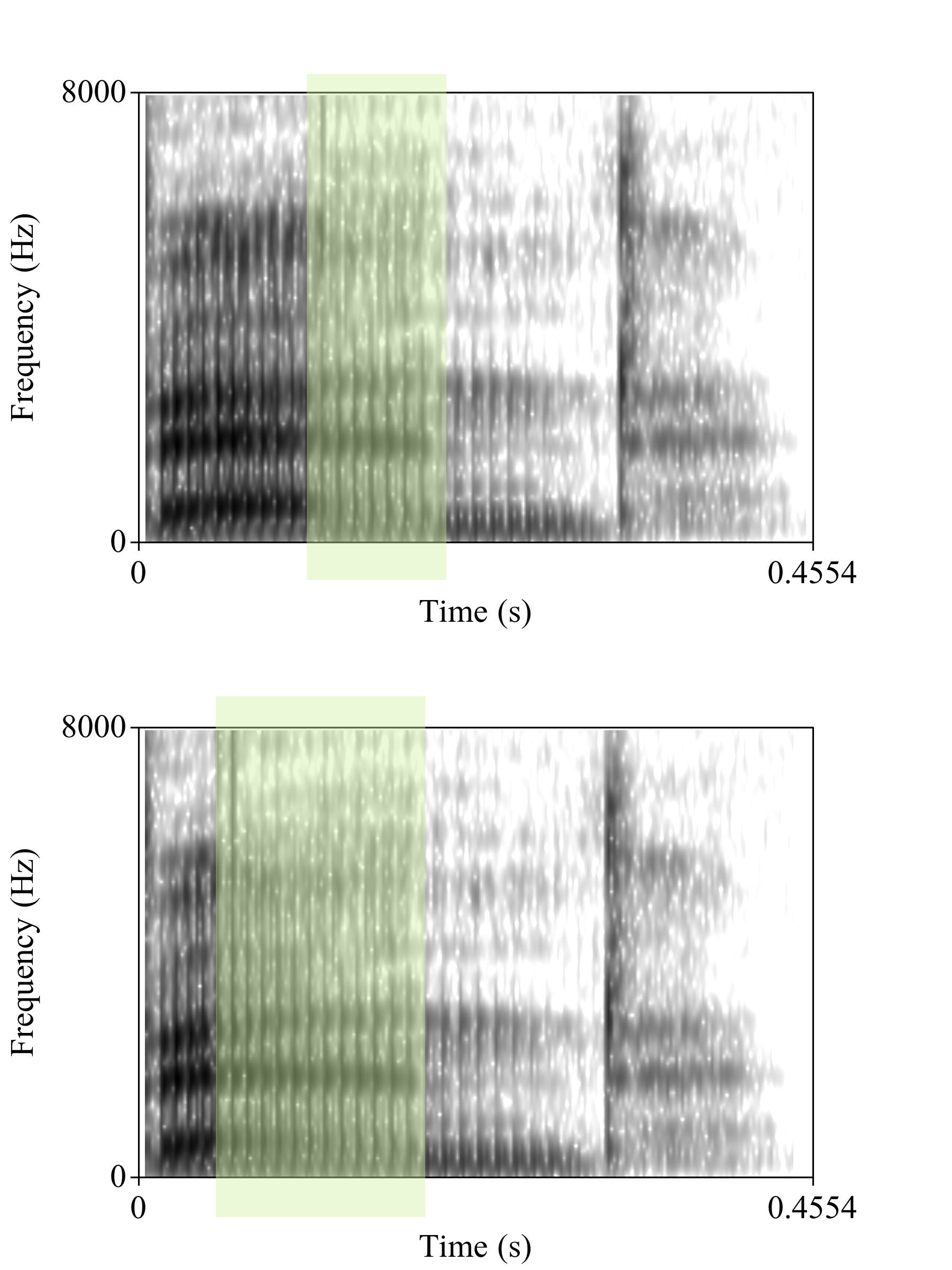
First, some quick background on how sounds like [p], [t], and [k] differ from sounds like [b], [d], and [g] at the beginning of English words like pit and bit. What word is this native American English speaker saying? Does it sound like ‘pit’ or ‘bit’ to you?
![spectrograms of [pɪt] and [bɪt]](images/pit-bit.png)
The image to the left is a spectrogram (frequency analysis over time) of the word pit. Hear the puff of air at the beginning? It is highlighted in blue.
pit and bit both start with the lips completely closed. One of the main differences between them is the duration of the puff of air, this duration is called VOT (voice onset time).
[pʰɪt]
[bɪt]
At least in American English, that puff of air is so important that if we cut it out of pit (this was that first sound you played! ‘pit’ with the puff removed) it results in a word that sounds to English-knowing listeners a lot like bit —though probably with maybe a funny [b], and that funniness is every bit as interesting and important as the change from [p] to [b]!
Another covarying feature is the way vowels before nasal consonants in English tend to be nasalized. Listeners can use this as soon as it becomes available, not only a large distinction like bend/bed…
but also a much more subtle distinction like the difference in nasalization between these two sound files. Can you hear a difference?
This first recording has late nasalization starting 100 miliseconds after the [b].
This second recording has early nasalization starting 33 miliseconds after the [b].
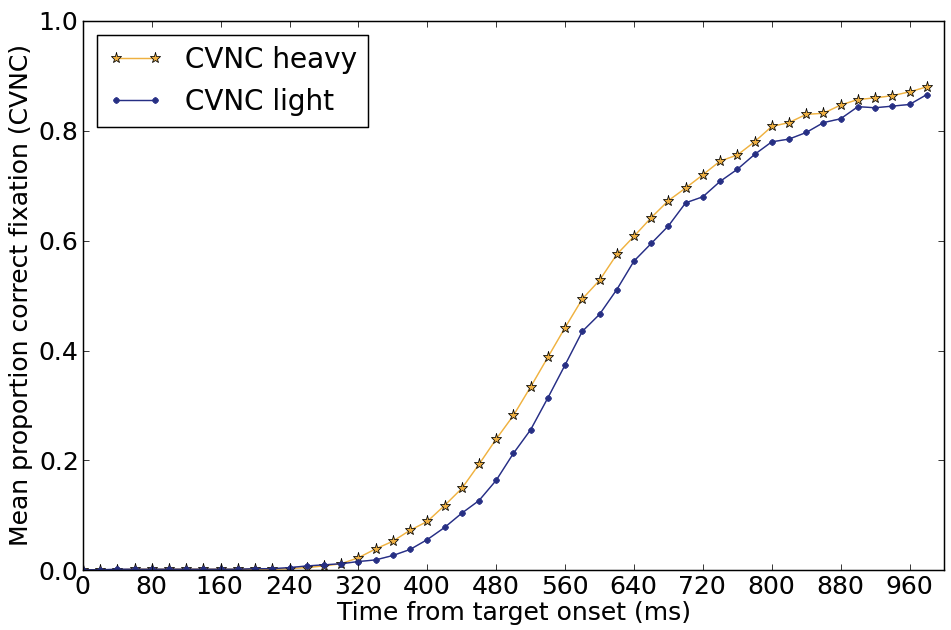
In an eye tracking task we found that listeners can use nasalization as soon as it is present. Looks to the heavily-nasalized word were, on average, 60 ms faster —the same average difference between early and late nasalization in the recordings (Beddor, McGowan, Boland, Coetzee, and Brasher, 2013).
Whether the information is social, contextual, articulatory, or idiosyncratic, we humans have an astonishing ability to attend to it, remember it, and activate it during perception. This ability, my research suggests, is not irrelevant to linguistic competence or even peripheral to it, it is fundamentally and centrally part of what it means to know and speak a human language.
 Thank you for reading! Ask me questions? And please enjoy this pigeon engraving as a free gift. And many, many thanks to my friend M.C. Nee for turning me into this cartoon.
Thank you for reading! Ask me questions? And please enjoy this pigeon engraving as a free gift. And many, many thanks to my friend M.C. Nee for turning me into this cartoon.